The purpose of this study is to analyze the intellectual structure of reading studies by using Co-Word Analysis based on the mixed weight in which the level of academic journals and the position of keywords are calculated. To achieve it, 838 academic articles relating to reading studies from KCI during the period from 2003 to 2012 were retrieved and 56 keywords were extracted. The results of clustering analysis, MDS, network analysis are that the network based on the mixed weight has a better performance in above three methods and reading studies can be divided into 4 bigger divisions and 11 subdivisions. Finally, the result of document analysis shows reading studies changes its research tendency from theoretical studies to empirical studies.
현대 사회의 모든 것은 너무나 빠른 속도로 움직이고 있고, 여기에 뒤떨어지지 않기 위하여 사람들도 가능한 한 모든 방법을 동원하여 변화를 추구하고 있다. 그 중에서 예나 지금이나 모두 한결같이 중요시한 것은 바로 독서이다. 독서는 단순히 글을 읽는 것을 넘어 지식을 쌓는 것뿐만 아니라 창의력, 상상력, 자기 문제해결 능력, 평생학습 능력, 여가 심지어 건강한 심리 및 정신을 형성하는데 도움이 준다. 독서의 중요성이 거듭 강조되면서 특히 최근 들어 독서의 열풍이 불기 시작하고, 독서분야에 자아존중감, 문식성 등 새로운 용어나 개념이 나타나면서 독서의 연구영역 구분이나 연구동향을 규명이 필요하다고 본다. 따라서 이 논문은 1980년대 프랑스에 처음 소개되었고, 그 후에 Callon이 논문과 책에서 소개한 단어동시출현 분석을 이용하여 독서분야의 지적구조를 규명하는데 그 목적이 있다(Callon et al. 1983; Callon, Law, and Rip 1986).
이 논문에서 관련된 선행연구는 크게 독서분야와 관련된 연구 및 단어동시출현과 관련된 연구 두 가지로 나뉜다.
첫째, 독서분야에 관한 선행연구는 장윤미 (2013)가 인용분석으로 독서치료의 주제 연구 문헌의 성격을 파악한 이외에 주로 독서치료를 중심으로 신체장애, 초등학생, 청소년 등을 대상으로 빈도분석을 한 논문이 대부분이다(장윤미 2013; 김선호 2011; 정수연, 이명규 2011; 한복희 2007). 이외에 김판준은 텍스트마이닝 기법인 저자 프로파일링을 이용하여 독서분야를 분석하였는데, 핵심저자와 이들의 저작을 중점으로 제한되어 있었고 독서분야의 세부영역에 대한 상세한 파악이 이루어지지 않았다(김판준 2011). 따라서 이 논문에서는 단순한 빈도분석을 넘어 사회 네트워크 분석, 다차원척도분석, 군집분석 등 다양한 다변량분석 기법을 활용하여 저자가 선정하고 논문의 주제를 잘 대표할 수 있는 키워드를 중심으로 독서분야의 체계적인 연구주제를 밝히고, 하위주제집단을 구분하며 집단 간의 관계를 밝히는 등 독서분야의 지적구조를 규정하자고 한다.
둘째, 단어동시출현과 관련된 논문은 주로 인공지능 분야, 한국의 국가 R&D, 의료정보학, 오픈 액세스분야, 한국어교육학을 대상으로 한 연구들이었다(이미경,정영미 2003; 서원철, 박현석, 윤장혁 2012; 허고은, 송민 2013; 서선경, 정은경 2013; 강범일, 박지홍 2013). 이외에 명칭은 다를 뿐 단어동시출현분석을 적용한 네트워크 분석으로 정보조직 분야 및 문헌정보학을 대상으로 한 연구들도 있었다(박옥남 2011; 조재인 2011). 그러나 이들 논문들은 학술지의 등급이나 키워드의 위치 등을 무시한 채 단어동시출현 기법을 사용하였다. 이 논문에서는 이 점을 고려하여 수평 가중치와 수직 가중치를 결합하여 산출한 혼합 가중치를 기반으로, 단어동시출현 방법을 적용하여 독서분야의 지적 구조를 규명하고자 한다.
지적구조는 특정 학문분야의 지식을 계량적 또는 관계적 데이터로 파악한 구조이고, 지적구조 분석을 통하여 특정 학문분야의 구조적인 특성, 연구동향, 세부주제 영역 그리고 그 분야에 나타난 학제성을 파악할 수 있다. 단어동시출현분석은 지적구조분석을 하는 중요한 방법 중 하나이다. 단어동시출현분석은 특정분야의 문헌 집합에 나타난 키워드나 용어쌍이 동시에 출현한 빈도를 계산하며 이 빈도로부터 단어의 유사도를 계산하고 다양한 통계기법을 통하여 해당 분야의 주제영역을 분류하고, 핵심주제를 파악하거나 주제영역 간의 관계를 발견하는 컨텐츠 분석기법이다. 물론 두 단어가 한 문헌에 동시에 출현하는 빈도가 높을수록 두 단어 간의 관련성이 높다는 것을 전제로 한다(이수상 2012).
따라서 문헌집합에서 추출한 각 키워드쌍이 동시에 한 문헌에서 나타난 빈도를 계산함으로써 이들 키워드간의 네트워크를 구성할 수 있다. 이 키워드 네트워크에서 각 키워드가 점이 되고 동시출현빈도가 키워드란 점 간의 연관도를 반영할 수 있다. 단어동시출현분석은 바로 이를 기반으로 키워드를 분석대상으로 삼고, 다양한 통계기법을 동원하여 복잡한 키워드네트워크에서 유용한 정보나 패턴을 살펴보고, 표나 그림 으로 표현하는데 유용하다.
그러나, 이와 같은 단어동시출현분석은 학술지의 등급, 즉 같은 키워드인데 저널영향력지수가 높은 학술지와 낮은 학술지를 구별하지 못한다. 같은 문헌임에도 불구하고 키워드의 중요도는 다르다고 볼 수 있다. 즉, 키워드는 보통 위치에 따라서 중요도가 달라진다. 예를 들면 주요키워드는 일반적으로 논문의 주제를 나타내며 첫 번째에 배치하고, 기타 키워드는 주요 키워드를 한정하거나 수식하는 것으로 뒤에 나타나는 것이 일반적이다. Nature 등 일부 국제적인 학술지의 저자 키워드를 중요도 순으로 적도록 (Authors listed in descending order of contribution) 하는 지침도 이와 같은 원칙이라고 볼 수 있다(Verhagen et al. 2003).
따라서 이 논문에서는 특정 학문분야의 연구주제를 잘 분석하기 위하여 키워드학술지의 등급을 나타내는 수평 가중치와 키워드의 위치를 나타내는 수직 가중치, 그리고 수평과 수직 가중치를 결합한 혼합 가중치를 도입하고, 일반가중치 및 혼합가중치에 의하여 생성한 키워드네트워크를 비교하여 독서분야의 지적구조를 분석하였다.
일반적으로 저널영향력지수에 따라 영향력지수가 높은 학술지와 영향력지수가 낮은 학술지로 구분한다. 수준 높은 논문은 보통 영향력지수가 높은 학술지에 게재하게 되고, 수준 높은 논문에서 나타나는 키워드도 해당 분야의 연구동향이나 연구주제를 더 잘 대표할 수 있을 것이다. 그러나 일반적으로 수준 높은 논문은 해당 분야의 모든 논문 중에서 차지하는 비율이 낮고, 저자가 수준 높은 논문을 발표하는 주기도 상대적으로 길다. 따라서 학술지의 등급은 단어동시출현분석에서 고려되어야 하며, 이를 나타내는 지표를 수평 가중치라고 하고, 계산방식은 한국학술지인용색인(Korea Citation Index; KCI)에따라서 <표 1>과 같이 세 가지로 구분한다

수평 가중치의 계산방식
일반적으로 키워드 A와 B가 같은 문헌에서 나타난다면, 이 두 개의 키워드의 빈도는 다 1이 되고 키워드의 중요성을 구분하지 못한다. 그러나 같은 문헌이라도 키워드의 위치에 따라서 분명히 키워드의 중요성이 달라진다. 따라서 이 논문에서는 키워드의 위치를 나타내는 지표를 수직 가중치라고 하고 계산방식은 <표 2>와 같다.

수직 가중치의 계산방식
혼합 가중치는 학술지의 등급 및 키워드의 위치를 결합하는 것이며 계산방식은 다음과 같다.
M=a*H+ (1-a) V
이 중에서 a는 상수이고 범위는 0에서 1까지 이다. a를 통하여 연구자가 수평 가중치와 수직 가중치의 비율을 조절할 수 있다. a=1일 때 혼합가중치가 수평 가중치로 변한다. 즉, 학술지의 등급만 고려하고 키워드의 위치를 무시하는 것이다. a=0 일 때는 혼합가중치가 수직 가중치가 되고 키워드의 위치만을 계산하는 방식이다. 따라서 연구자가 연구 분야의 특성에 따라 학술지의 등급과 키워드 위치의 비율을 조절할 수 있다. 이 논문에서는 a를 0.5로 설정함으로써 학술지 등급과 키워드의 위치를 동등하게 간주한다.
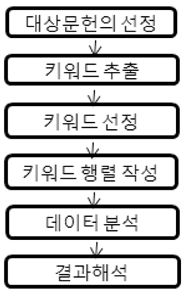
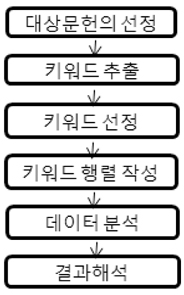
이 연구에서 적용한 데이터 분석 절차는 <그림 1>과 같다.
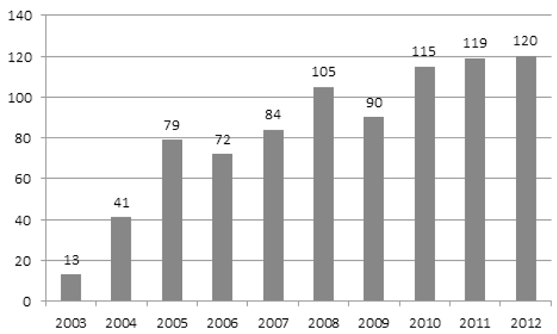
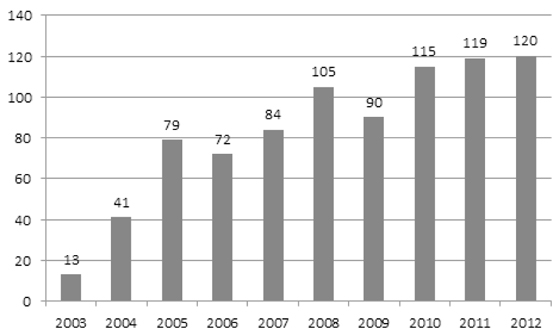
KCI에 독서란 키워드를 기입하고 기간은 2003년 1월에서 2012년 12월까지로 지정한 결과 총 838건의 문헌이 나왔다. 연도별로 독서와 관련된 논문을 살펴보면 <표 3>과 같다.
<표 3>에서 보는 바와 같이 2003년에서 2012년까지 10년 사이의 문헌의 추이를 살펴보면, 2004년, 2005년에 독서와 관련된 논문이 많이 증가하기 시작하였고, 2008년 한해에 100건의 논문이 넘었으며 2010년부터 또 다시 늘어나기 시작하였다. 2012년의 논문량을 2003년의 논문량과 비교하여 보면 거의 10배나 증가하였다. 이를 나타내면 <그림 2>와 같다.
<그림 2>를 보면 지난 10년 동안 독서와 관련 된 연구가 꾸준히 상승세를 보인다는 것을 알 수 있다. 이것은 2000년대에 접어들면서 독서에 관한 사회적 인식이 고조됨에 따라 초·중·고 학교에서뿐만 아니라 도서관과 기타 공공기관, 서점, 매체 및 각종 단체에서 독서교육을 중요시하고, 다양한 독서프로그램을 개발한데서 그 이유를 찾을 수 있다(윤금선 2008).

연도별 문헌수
한편 그림을 살펴보면 2004년, 2005년의 상승세가 제일 현저히 나타났다. 이것은 2004년부터 대학입시에서 본고사를 폐지하고 독서감상문 점수를 중요시하는 제도가 나오면서 독서의 중요성이 강조되었기 때문이다(김승환 2006, 67). 그리고 정부 차원에서 문화관광부가 2005년에 “독서문화진흥법안”을 발표함으로써 독서교육에 대해 법적으로 이의 내실화 도모에 힘썼기 때문인 것으로 보인다(김상옥 2012, 42-63). 이외에 ‘교육인적자원부’가 2008년도 대학 입시개선안에서, 독서교육을 활성화시켜 대입에 적극 반영하겠다는 것도 독서와 관련된 연구가 한해에 100편이 넘은 이유라고 할 수 있겠다(윤금선 2006, 279).
또한 연도별 문헌수를 보면, 이 논문에서 추출한 문헌수가 김판준(2011)이 추출한 것보다 다소 적게 나온 이유는 김판준 논문이 기사까지 분석대상에 포함시킨 반면에, 이 논문에서는 학술지 논문을 중심으로 분석하였기 때문이다.
두 번째 단계에서 키워드를 4,997개(문헌 당5.9개) 추출하였으나 이 중에서 동의어, 유사어등을 한국문헌정보학색인, 한국십진분류법 6판등을 통하여 단어를 정규화한 결과 키워드가 총 3,175개 남았다. 키워드수가 너무 많아서 분석이 불가능하여, 孙淸蘭가 1992년에 제시한 공식을 이용하였다. 孙淸蘭은 Donohu.J.C이 1973년에 키워드의 빈도수에 따라 높은 빈도수의 키워드와 낮은 빈도수의 키워드를 구분하는 공식을 만들었는데, 이를 수정하여 키워드 종수만 알아내면 고빈도 키워드를 선정할 수 있는 공식을 제안하였다(Donohu 1973; 孙淸蘭 1992). 이 공식은 다음과 같고 여기서 D는 키워드 종수다.
n = (-1+ 1+ 4D)/2
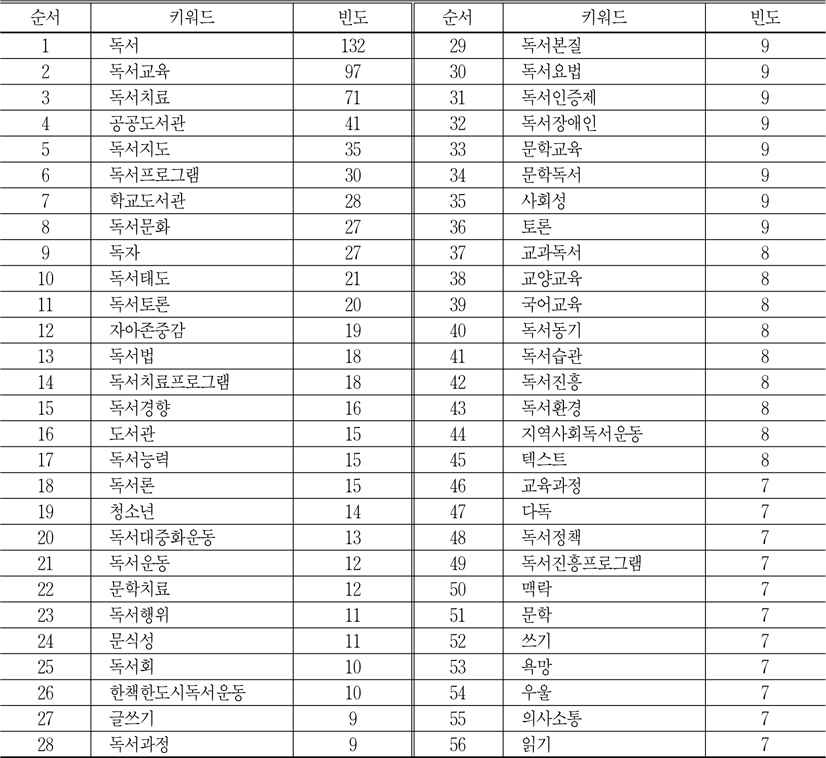
위 공식에 의하여 키워드 56개를 최종 분석 대상으로 선정하였고 선정된 키워드 리스트는 <표 4>와 같다. 선정된 키워드는 모두 7회 이상 나타났고 그중에 독서가 132회로 제일 많고, 독서교육 97회, 독서치료 71회, 공공도서관 41회, 독서지도 35회 등으로 나타났다.
이렇게 선정된 키워드는 우선 Excel에서 (문헌, 키워드), (문헌, 키워드, 가중치)의 쌍을 작성한 다음에, UCINET의 문헌-키워드 및 키워드-키워드 행렬(56*56)로 변환하였다. 그 다음에 선정된 키워드를 분석하기 위하여 SPSS로 키워드 간의 연관도를 산출하는데, 일반적으로 코사인 유사도와 피어슨 상관 유사도를 적용한다. 코사인 유사도는 키워드 사이의 직접적인 연관성을 측정하는 것이고 네트워크 분석에 사용한다. 코사인 유사도는 0에서 1 사이에 있으면서 수치가 높을수록, 두 단어 간의 유사도가 높음을 알 수 있다. 이와 달리 피어슨 연관성 유사도는 각 키워드의 간접적인 연관성을 나타내고 주로 시각화하는데 유용하게 사용한다. 피어슨 상관계수에 의해 산출된 값은 -1에서 1 사이에 있고 관계의 크기와 방향을 동시에 나타낸다. 코사인유사도와 마찬가지로 상관계수 값이 높을수록 단어 간의 유사도가 더 높은 것이다.
선정된 56개 키워드 리스트
<표 5>는 일반가중치와 혼합가중치에 따라 코사인 유사도가 가장 높은 앞 4개의 키워드쌍이다.
<표 5>에서 보는 바와 같이 일반가중치와 혼합가중치에서 산출된 키워드쌍이 똑같지만 혼합가중치에서 산출된 값이 모두 일반가중치보다 크게 나타난 것을 알 수 있다. 그리고 코사인유사도가 가장 높은 키워드쌍은 한책한도시운동-지역사회독서운동, 독서대중화운동-도서관, 독서대중화운동-독서경향, 도서관-독서경향으로 나타났다. 이들은 다 독서대중화운동과 관련된 키워드이며, 독서대중화운동은 원래 개인적인 공간에서 하는 독서행위에서, 지역사회 시민들과 함께 책을 읽고 교감하는 독서운동으로 그 폭을 넓혔다. 2003년부터 서산시립도서관에서 실시한 한책한도시운동은 역시 대표적인 독서대중화운동의 하나이며, 지역사회에서 선정된 한 책을 읽고 토론을 하는 등 다양한 독서프로그램을 통하여 지역사회 구성원의 독서를 유도하는 독서운동이다. 이 한책한도시독서운동은 최근까지도 여러 도서관에서 실시되고 있다(조찬식 2013, 201-221).

키워드쌍의 코사인 유사도
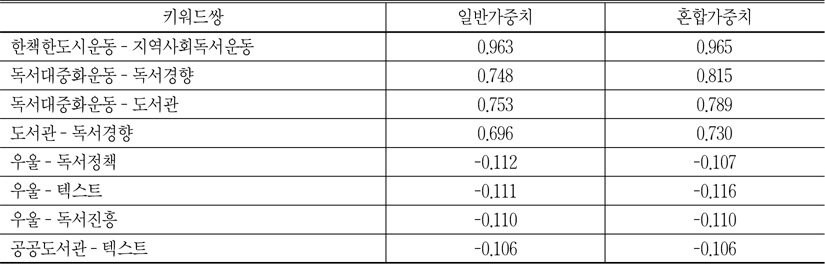
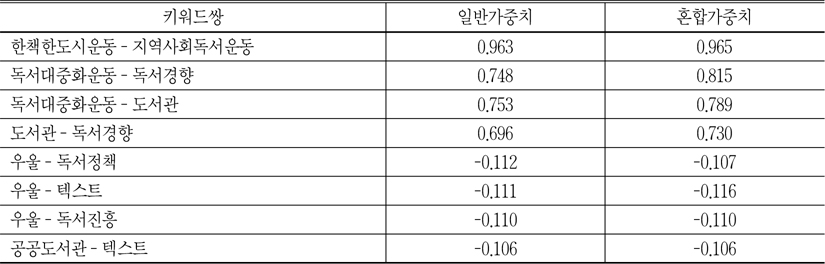
<표 6>은 키워드 간의 동시출현빈도를 피어슨 상관 유사도로 정규화한 행렬로 가장 높은 4개의 키워드쌍과 음의 값으로 가장 낮은 4개의 키워드 쌍을 산출한 것이다.
<표 6>에서 살펴보는 바와 같이, 코사인 유사도와 마찬가지로 혼합가중치에 의해 산출된 피어슨 상관 유사도도 정적의 값뿐만 아니라, 음의 값에서도 일반가중치로 산출된 유사도보다 높거나 같은 것으로 나타났다. 한책한도시운동-지역사회독서운동의 상관계수가 0.9를 넘어서아주 강한 상관관계를 갖고, 독서대중 화운동-독서경향, 독서대중화운동-도서관, 도서관-독서경향의 상관계수도 0.7에서 0.8 사이에 있어 비교적 높은 상관관계가 있다는 것을 알 수 있다. 또한 음의 가장 큰 값은 우울-독서정책, 우울-텍스트, 우울-독서진흥, 공공도서관-텍스트로 나타났는데, 이들은 상관계수의 절대치가 0.2 이하로 무시할 만한 상관관계를 갖고 있는 것으로 해석할 수 있다(오택섭, 최현철 2003).
키워드쌍의 피어슨 상관 유사도
군집분석은 여러 대상을 잘 구별할 수 있는 여러 변인을 이용하여 동질적인 집단을 찾아내는 방법이며, 여기에 코사인계수로 계층적 클러스터링 기법인 Ward기법을 사용하여 제곱유클리디안 거리를 사용하였다. <표 7>은 일반 가중치와 혼합가중치에 따라 56개 키워드를 5개 군집으로 구분한 것이다.
<표 7>에서 보는 바와 같이 군집의 크기를 보면 혼합가중치에 의하여 도출한 군집크기가 일반가중치에 의한 것보다 비교적 균형있는 것으로 나타났다.
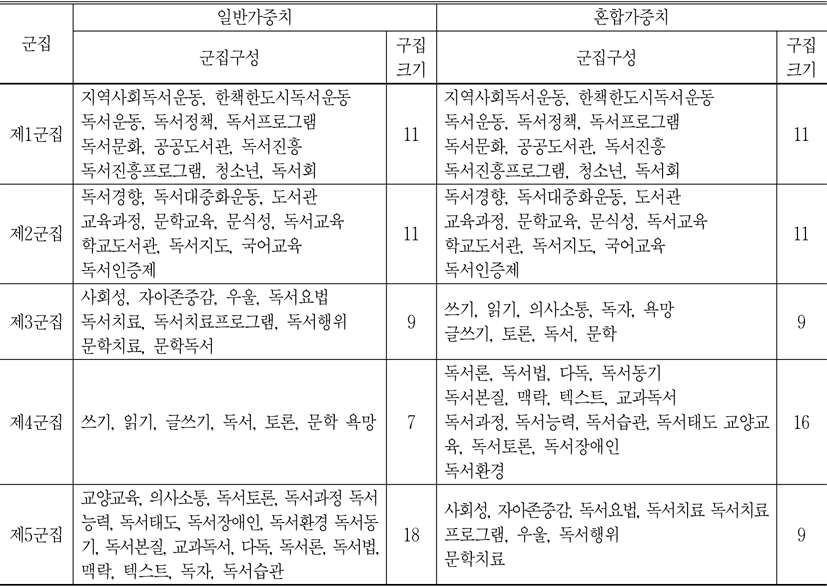
군집분석에 의한 5개 군집
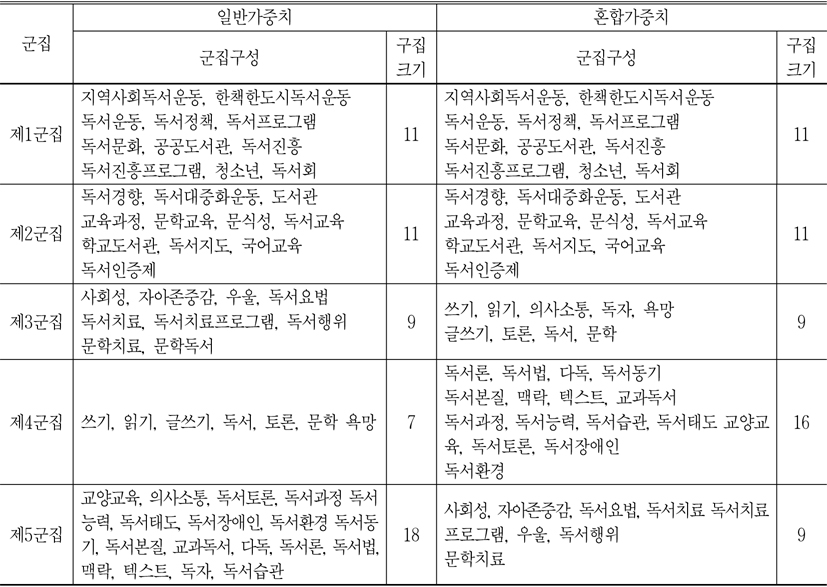
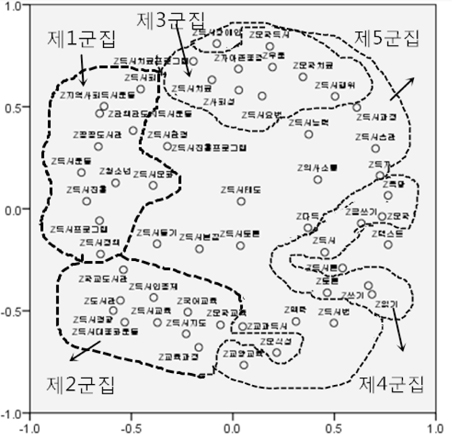
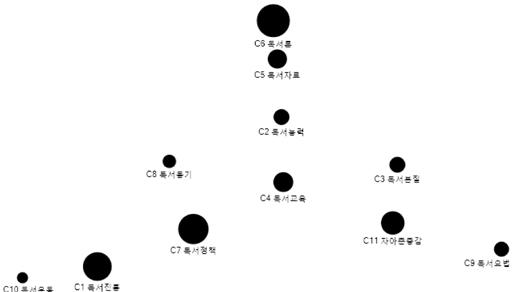
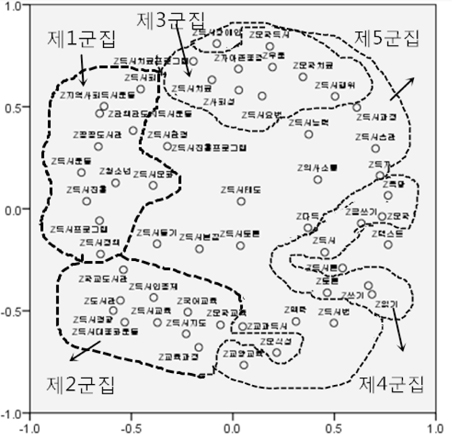
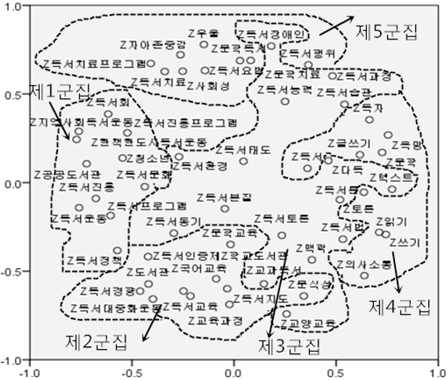
군집분석에 의해 형성된 군집의 결과를 보완하기 위하여 다차원척도분석을 실시하였다. 다차원척도분석은 대상 자료간의 유사성 혹은 비유사성 측정 결과를 저차원 공간에 점간의 거리로 나타내는 기법이다. 여기서 상관계수를 Z점수로 표준화하여 유클리드 거리를 산출한 후 PROXSCAL알고리즘을 사용하는 방식으로 수행하였다. 일반가중치와 혼합가중치에 따라 작성한 <그림 3>과 <그림 4>는 다음과 같다.
<그림 3>, <그림 4>에서 보는 바와 같이 일반가중치에 의하여 구분한 군집들 같은 경우, 같은 군집에 속함해도 불구하고 형성된 군집은 영점으로 널리 펴져나가고 있는 것으로 나타났다. 특히 제5군집은 제일 위와 제일 밑에 있는 점이 너무 멀리 떨어져있는 것을 볼 수 있다. 반면에 혼합가중치에 의하여 구분한 군집의 위치는 제1군집이 왼쪽에, 제2군집이 아래에, 제3군집이 중간에, 제4군집이 오른쪽에, 제5군집이 위에 있는 것으로 나타났다.
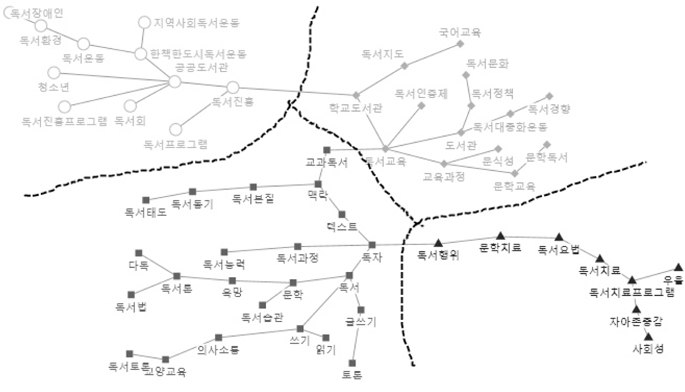
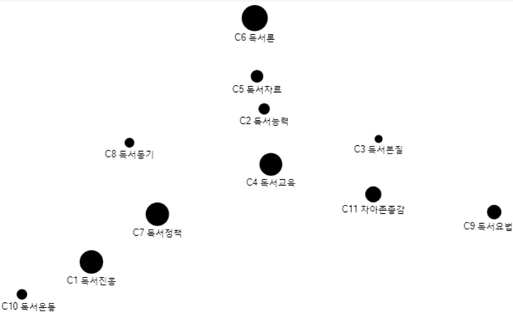
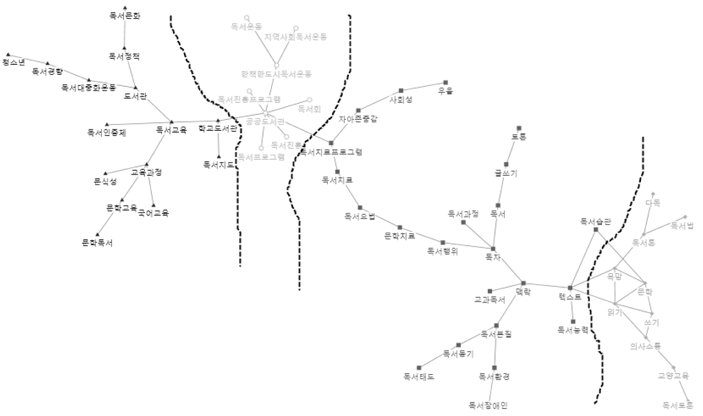
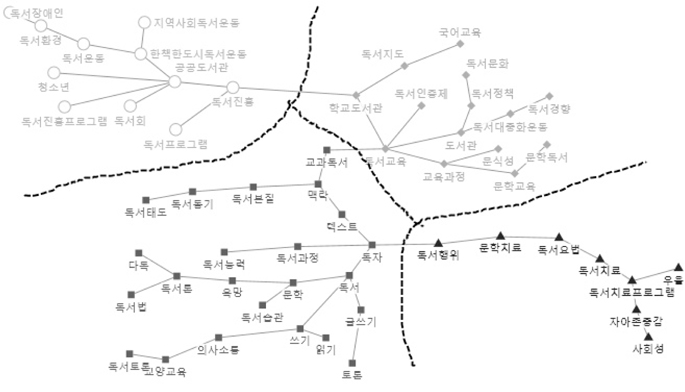
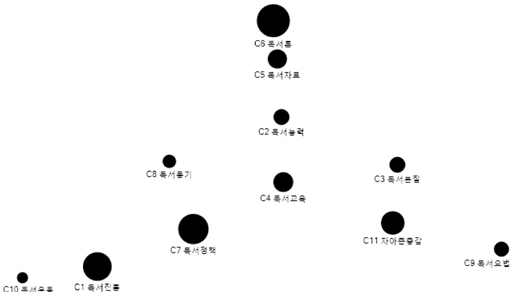
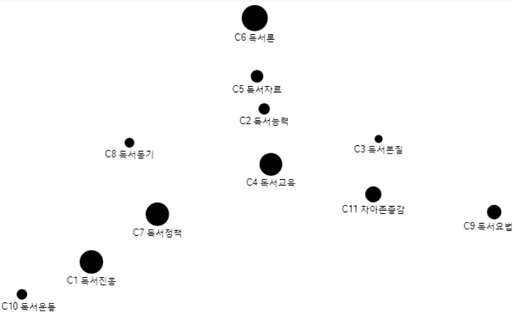
네트워크분석의 목적은 중심성 분석 및 하위집단 구분을 통하여 대량의 정보속에 숨겨져 있는 특별한 유형의 패턴을 찾아서, 그 의미를 파악할 수 있도록 가시적인 형태의 결과물을 보여주는 것이다. WNET프로그램으로 코사인 유사도행렬을 입력하여 PFnet(패스파인더 네트워크), PNNC(병렬 최근접 이웃 클러스터링), WCENT(네트워크중심성)의 세 개 텍스트 파일을 생성하였다(이재윤 2013). PFnet는 전체구조와 세부 구조의 표현 능력이 모두 뛰어나고, 각 노드마다 중요한 링크만 남기는 방식으로 축약하므로 전체 구조를 한 눈에 파악하는데 도움이 된다(이재윤 2006a). PNNC는 병렬 최근접 이웃 클러스터링기법이며, 전통적인 군집분석이 군집의 수를 결정하는데 다소 자의적인 반면에, PNNC는 군집의 수가 자동적으로 결정된다는 효과성과 효율성이 있는 장점이 있다(이재윤 2006b). <그림 5>, <그림 6>은 WNET프로그램을 사용하여 산출한 PFnet와 PNNC를 이용하여 NodeXL에 입력하여 시각화한 것으로,<그림 5>는 일반가중치, <그림 6>은 혼합가중치에 의하여 그린 것이다.
<그림 5>, <그림 6>에서 보는 바와 같이 일반가중치에 의한 클러스터링은 오른쪽 밑에 있는 군집을 보면 군집 간에 얶힌 부분 있는 것으로 나타났다. 반면에 혼합가중치에 의한 클러스터링은 각 군집의 구성이 가까이 뭉쳐있고 네 개의 군집이 뚜렷하게 구분되어 나타난다.
이상으로 혼합가중치에 의한 행렬은 일반가중치에 의한 것보다 군집분석, 다차원척도분석, 네트워크 시각화에서 더 좋은 결과가 나타난 것 을 알 수 있다. 따라서 이와 같은 혼합가중치에 의한 행렬을 이용하여, 집중적으로 네트워크분석을 통하여 독서분야의 지적구조를 규정해보<그림 5>, <그림 6>에서 보는 바와 같이 일반 가중치에 의한 클러스터링은 오른쪽 밑에 있는 군집을 보면 군집 간에 얶힌 부분 있는 것으로 나타났다. 반면에 혼합가중치에 의한 클러스터링은 각 군집의 구성이 가까이 뭉쳐있고 네 개의 군집이 뚜렷하게 구분되어 나타난다.이상으로 혼합가중치에 의한 행렬은 일반가중치에 의한 것보다 군집분석, 다차원척도분석, 네트워크 시각화에서 더 좋은 결과가 나타난 것을 알 수 있다. 따라서 이와 같은 혼합가중치에 의한 행렬을 이용하여, 집중적으로 네트워크분석을 통하여 독서분야의 지적구조를 규정해보기로 한다.
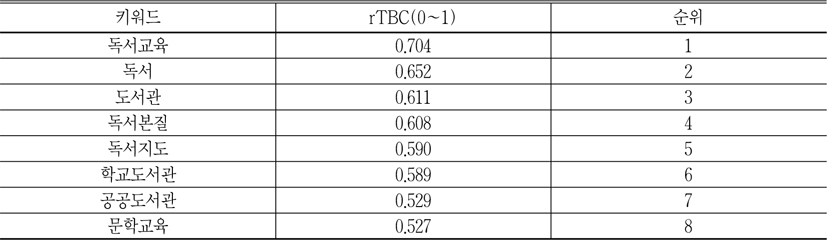
삼각매개중심성은 한 노드가 다른 노드들 사이를 결속시켜주는 능력을 측정하는 것이고, 삼각매개중심성이 높은 노드는 다른 노드 간의관계 개선에 기여하는 정도, 즉 중재력 또는 결속력이 강하다는 것을 의미하며 이런 노드는 항상 전역적 핵심노드로 간주한다. 반면에 군집을 단위로 삼각매개중섬성을 측정한다면 각 군집 안에 노드의 삼각매개중심성이 국지적 중심성이 되고, 군집별 삼각매개중심성이 제일 높은 노드가 해당군집의 대표 키워드가 된다(이재윤 2006c). 이 논문에서는 56개 키워드의 삼각매개중심성을 측정하였는데, 높은 중심성값을 얻은 키워드는 독서분야에 영향력이 높은 키워드이고 핵심주제라고 볼 수 있다<표 8>은 혼합가중치에 의한 앞 8개 키워드의 전역적인 삼각매개중심성이다
<표 8>을 보면 전역적인 삼각매개중심성이 제일 높은 키워드는 독서교육이다. 이는 독서분야에서 독서교육을 제일 많이 연구하고 있는 것을 의미하며, 독서교육이 독서분야의 핵심영역이라고 할 수 있다.
특히 여기서 독서교육은 학교에서뿐만 아니라 사회, 가정에서도 이루어질 수 있는데, 삼각매개중심성이 높은 키워드를 보면, 독서분야의 핵심영역은 공공도서관에서나 학교도서관에서 이루어지고 있는 독서교육 위주로 한정하고 있는 것을 알 수 있다. 문헌정보학용어사전에 의하면, 독서교육은 독서자료를 매체로 자기생활을 충실하게 하고 사회생활에 적응하도록 인격형성을 계획적으로 도와주는 교육이라고 정의하고 있다. 반면에 독서지도는 인간형성을 위한 독서하는 태도, 지식, 기술능력, 흥미, 습관 등의 형성과 개발의 지도를 의미하는 독서교육의 실천적인 활동이라고 할 수 있다(문헌정보학용어사전 편찬위원회 2010). 따라서 이 논문에서 독서교육은 독서지도의 상위개념이라고 간주한다.
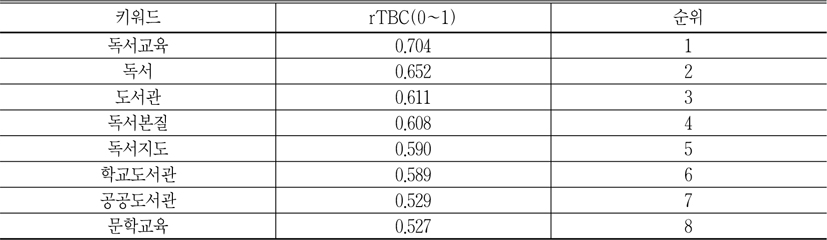
앞 8개 키워드의 전역적 삼각매개중심성
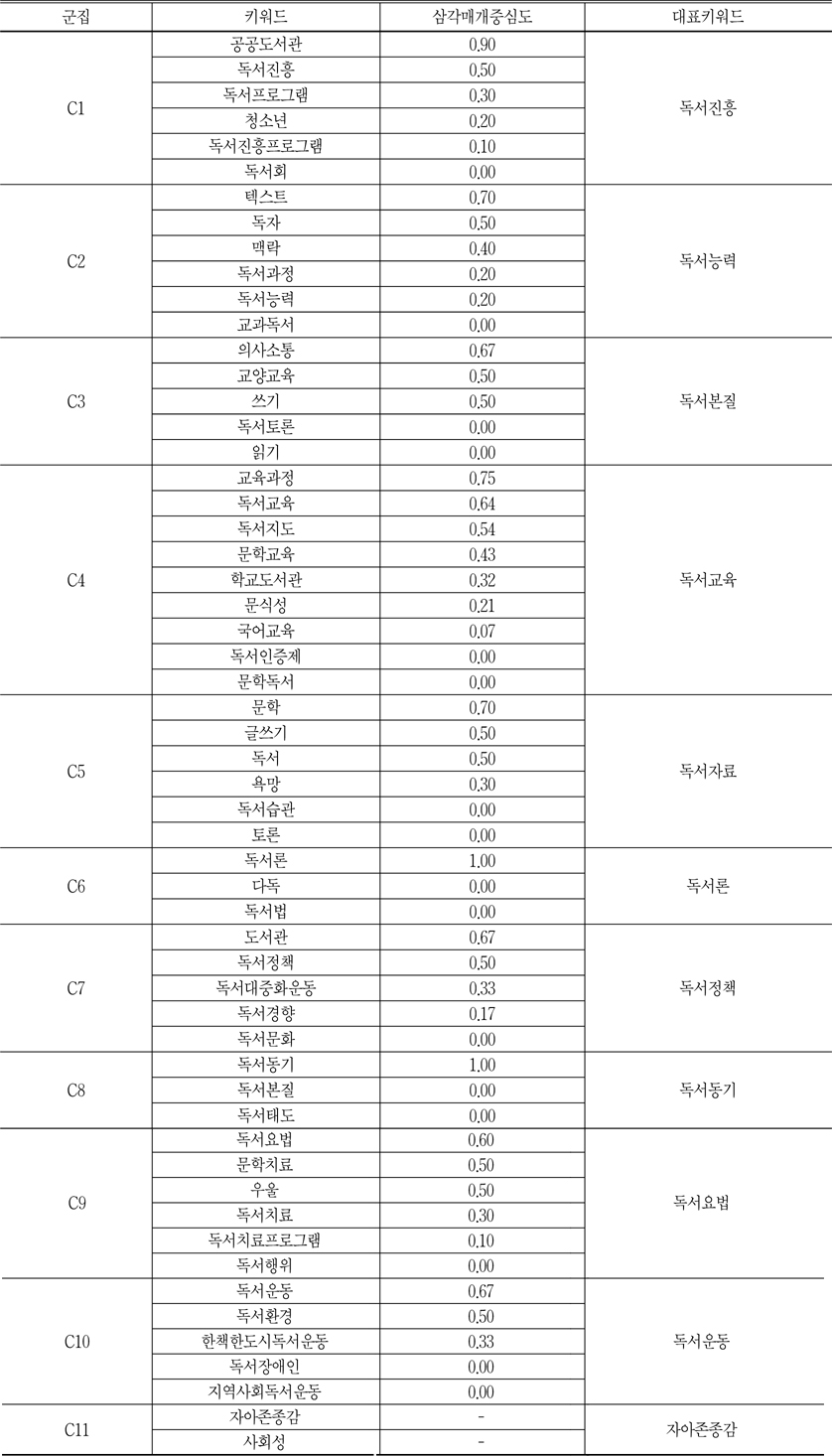
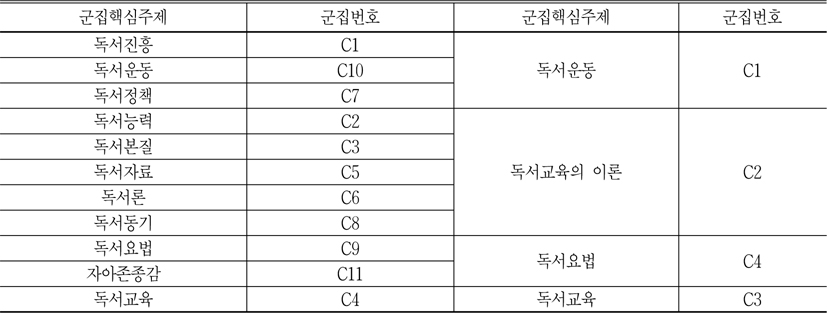
PNNC기법에 의하여 56개 키워드가 11개 군집으로 나타났다. 이 11개 군집에서 각 군집의 대표 키워드를 산출하기 위하여, 각 군집을 구성한 키워드의 행렬을 다시 WNET프로그램에 입력하고, 각 군집의 지역적 삼각매개중심성을 계산하였다.<표 9>는 11개의 군집과 각 군집의 대표 키워드이다.
각 군집에서 삼각매개중심성이 제일 높은 키워드는 해당 군집의 핵심키워드이고 따라서 군집의 이름도 핵심키워드가 되는 것이 일반적이다. <표 9>에서 보는 바와 같이 군집 1 중에서 공공도서관과 독서진흥은 다른 키워드보다 삼각매개중심도가 훨씬 높다. 따라서 군집 1은 공공도서관과 독서진흥과 관련된 주제라고 할 수 있다. 독서진흥은 주로 도서관 및 독서진흥법 등 법령과 관련되어 있다. 그리고 이런 법령에 의하여 국립중앙도서관의 지원과 지도를 통해, 공공도서관은 독서의 생활화를 위한 계획을 수립하고, 국민들에게 독서교육의 기회를 제공하는 독서프로그램을 장려하는 독서진흥 행사를 적극적으로 추진해야 한다고 규정하고 있다(김승환 2006). 따라서 군집 1은 독서진흥으로 명칭하였다.
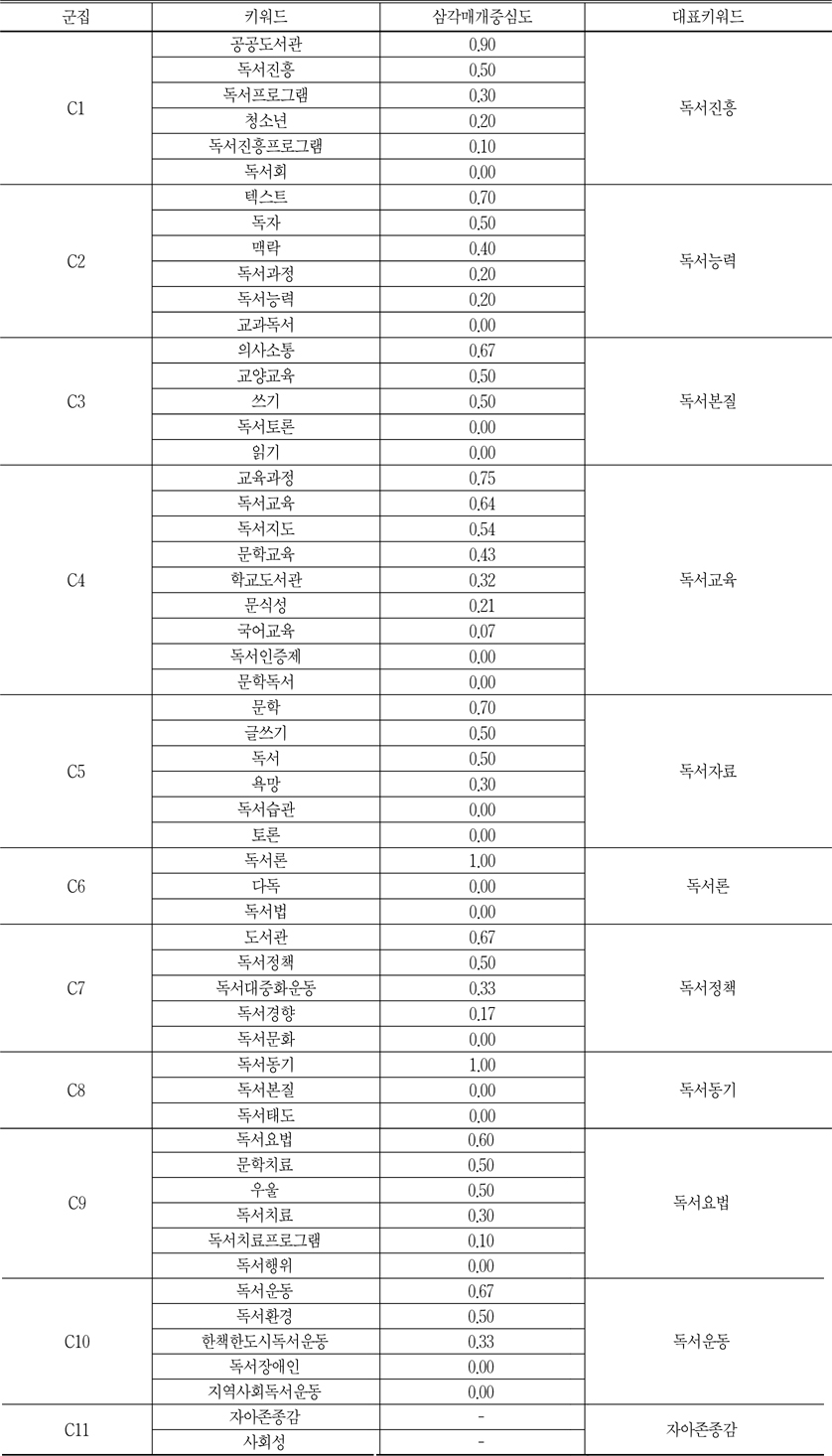
11개의 군집과 각 군집의 대표 키워드
군집 2는 독서능력이란 명칭을 붙였다. 변우열은 독서능력은 독서과정에 독자가 자료의 내용을 읽고, 텍스트의 맥락을 파악하는 능력이라고 정의하였다(변우열 2009). 또한 교과독서의 삼각매개중심도는 0이 되고 독서능력이 군집 2의 내용을 충분히 포괄할 수 있음을 알 수 있다.
군집 3의 명칭에 대하여 독서의 정의를 살펴보면, 넓은 개념으로 독서는 저자가 기호화된 의미와 독자의 뇌 사이에 일어나는 커뮤니케이션 활동으로서, 독자가 새롭게 의미를 재생하는 개인의 능동적이고 전략적인 사고과정이라고 한다(김효정 외 1992). 이런 저자와 독자 사이에서 형성한 의사소통을 통하여 독자는 저자의 인생관이나 가치관의 영향을 받아 자신의 품위있는 인생을 위한 가치관 및 교양을 얻을 수 있다. 이 모든 것을 종합하면 독서본질에 대한 내용이라고 할 수 있으므로 군집 3은 독서본질이란 명칭을 붙였다.
군집 4의 독서교육은 특히 성장하고 있는 아동과 학생들에게 인간형성, 사고력 및 창의력수준을 향상하는데 효과가 현저하기 때문에, 주로 학교도서관을 중심으로 체계적이고 과학적인 교육과정이 이루어지고 있다. 따라서 독서교육이 핵심적인 교육서비스로 제공되고 있는 것이다(변우열 2009). 그리고 앞서 언급한 바, 독서지도는 협의적으로 독서교육의 일종의 실천이므로 군집 4를 독서교육으로 명칭하였다.
군집 5에 대하여 문학은 넓은 의미에서 소설, 시, 수필 등 모든 독서자료를 다 포함할 수 있지만, 아동 및 청소년의 발달단계에 맞추어 그들의 욕망을 일으킬 수 있는 독서자료를 선정하는 것이 중요하기 때문에, 독서자료가 군집 5의 명칭이 되는 것이 타당하다고 볼 수 있다.
이외에 독서운동의 양상을 보면 일제강점기에서 1999년까지 국가차원에서 도서관을 중심으로 독서정책 및 법률을 제정하고 독서문화만 조성하는 독서대중화운동이 있는가 하면, 2000년 이후 어느 정도 독서환경이 조성되면서 지역, 도시를 단위로 회원을 모집하고 독서교육을 지도해주는 독서운동도 있다(김승환 2006). 따라서 군집 7은 독서정책으로, 군집 10은 독서운동으로 명칭하였다.
군집 9의 독서요법은 문헌정보학용어사전에 의하면, 정신건강상 예를 들면 우울 또는 신체 의학상 치료를 목적으로 독서를 시키는 치료방법이라고 정의를 내리고 있다(문헌정보학용어사전 편찬위원회 2010). 최근에 시, 그림책, 소설 등을 포함한 문학치료 이외에 음악치료, 미술치료, 놀이치료 등 독서요법의 적용범위를 넓혔지만, 문학치료는 여전히 독서요법의 주요 형식이다. 또한 치료는 전문가인 의사의 처방이나 지시가 있어야만 가능한 것이기 때문에 독서치료란 용어보다 독서요법이 더 적합하다고 할 수 있다(변우열 2009). 따라서 군집 9는 독서요법이라 명칭하였다.
군집 6과 군집 8은 세 개의 키워드만 있기 때문에 삼각매개중심성이 있는 키워드 하나만 있고 그것이 군집의 명칭이 된다. 따라서 군집 6과 군집 8은 각각 독서론과 독서동기로 명칭하였다. 마지막으로 군집 11은 두 개의 키워드만 있기 때문에 삼각매개중심성을 계산할 수 없고, 두 키워드 중에 빈도수가 높은 키워드인 자아존종감이 군집의 명칭이 된다.
이러한 결과는 김판준 논문에서 독서분야를 독서자료, 독서정책 및 독서운동, 독서치료, 독서자료를 9개 하위주제로 구분한 것과 일치하기는 하나, 이외에 김판준 논문에서 분석하지 못한 최근 2년 동안의 160편 논문을 분석하였고, 독서본질, 자아존중감과 같이 새로운 이론과 개념을 독서분야의 세부영역으로 규정하였기 때문이다.
그러나 이 <표 9>를 보면 독서요법 및 자아존중감, 독서진흥 및 독서운동, 독서자료 및 독서능력 등은 11개 군집에서 하나의 주제로 볼 수 있음에도 불구하고 다른 군집에 흩어져있다. 따라서 11개 군집을 4개로 줄이는 것이 분석에 더 도움이 된다고 할 수 있다. 11개 군집으로부터 결합해나가는 절차는 다음과 같다.
56개 키워드의 코사인 유사도 행렬은 11개 군집을 기반으로 키워드-군집의 56*11의 행렬을 생성한다. 즉 각 키워드는 11개 군집과의 코사인 유사도를 구한 것이고, 키워드가 해당 군집에 속한 경우에 키워드와 군집의 코사인 유사도는 1이 된다. 군집1의 공공도서관과 군집 6(독서론, 다독, 독서법)의 유사도는 예를 들면 다음과 같다.
cos(공공도서관, 독서론)=0.035 cos(공공도서관, 다독)=0.015 cos(공공도서관, 독서법)=0.042 cos(공공도서관, 군집 6)=(0.035+0.015+0.042)/3=0.031 cos(공공도서관, 군집 1)=
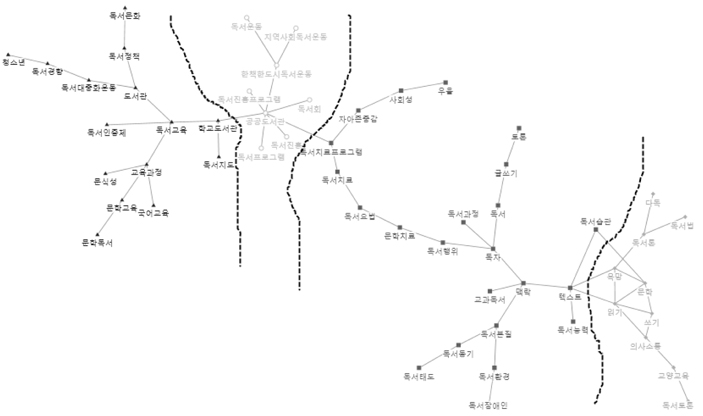
따라서 이를 유추하여 키워드-군집간의 56*11 행렬을 산출하였고, 군집-군집 간의 11*11 코사인 유사도 행렬도 산출할 수 있으며, 이를 NodeXL로 시각화하면 <그림 7>과 같다.
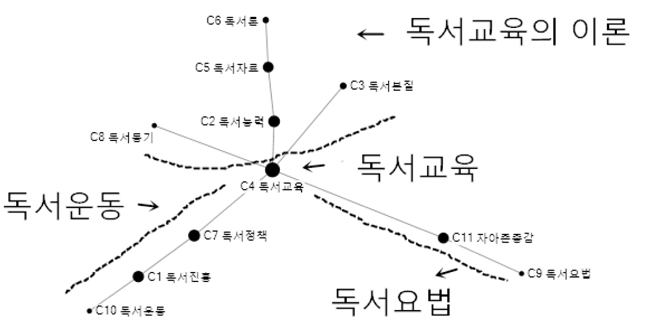
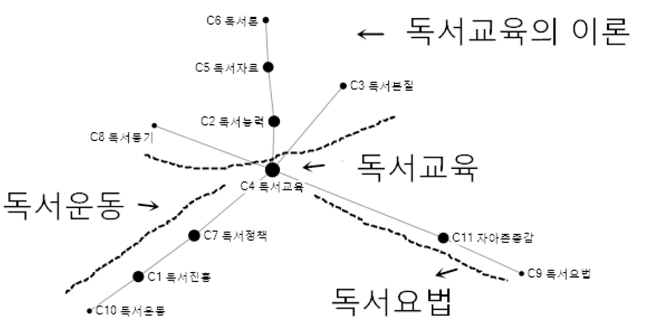
<그림 7>을 살펴보면 56개 키워드로 나누어진 11개 군집이 다시 4개의 군집으로 구분된다. 독서진흥은 도서관과 관련된 법제로 인하여 독서정책으로 포함되고, 독서정책은 앞에 설명하듯이 독서문화를 조성하는 일종의 독서운동이니, C1 독서진흥, C7 독서정책, C10 독서운동을 하나로 묶어서 독서운동이라고 한다. 그리고 자아존중감과 독서요법을 보면, 독서요법의 목적은 바로 독서를 통하여 개인적인 통찰과 자아존중감을 증진시키는 것이므로, C9 자아존종감과 C11 독서요법을 독서요법으로 합친다. 마지막으로 앞에 설명했듯이 C2, C3, C5, C6,C8은 독서교육을 실시하기 위한 이론이므로, 이들을 독서교육의 이론이라고 한다. 그래서 독서분야는 다시 독서교육, 독서교육의 이론, 독서운동, 독서요법의 4개 하위주제로 구분할 수 있다.
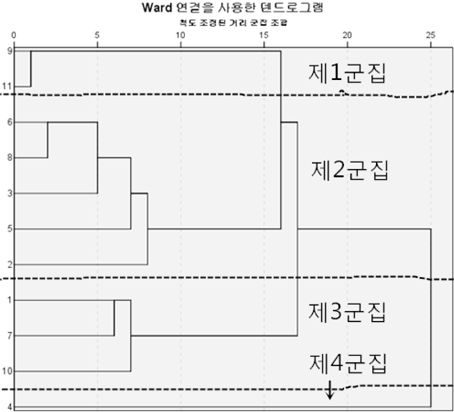
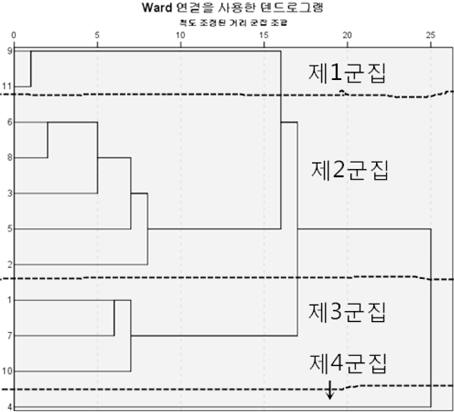
다음은 군집분석을 통하여 이를 검토한 것이다. 여기서 군집분석은 계층적 클러스터링 기법인 Ward기법을 통해서, 제곱 유클리디안 거리를 사용하여 <그림 8>과 같은 덴드로그램으로 나타낼 수 있다. 이 그림을 봐도 11개 군집을 쉽게 다시 4개 군집으로 묶을 수 있다는 것을 알 수 있다.
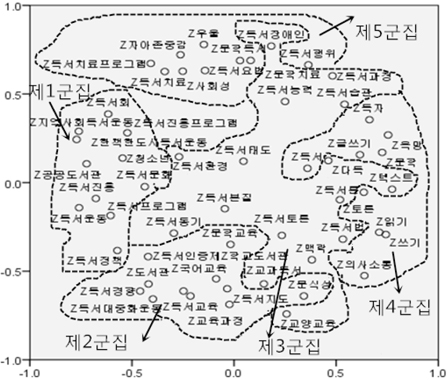
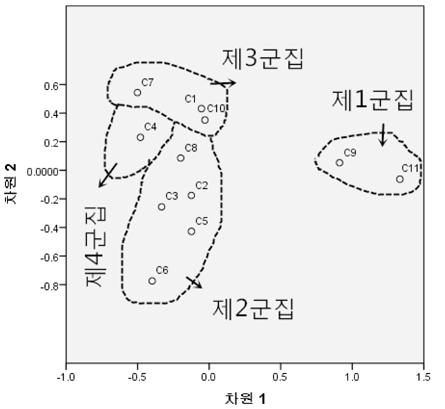
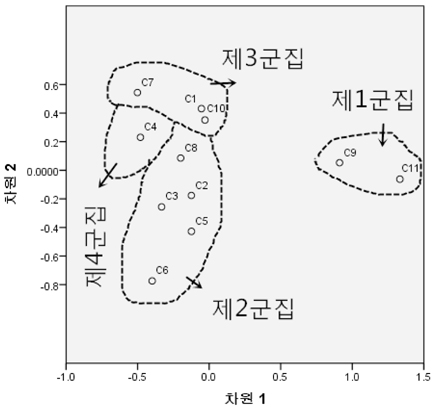
다음으로 다차원척도분석을 통하여 11개 군집의 위치를 알아보도록 하고 군집분석에 의해 형성된 군집 결과를 보완하도록 하였다. 상관계수의 유클리드 거리를 산출한 후 PROXSCAL 알고리즘을 사용하는 방식을 채택하였으며, 결과는 <그림 9>와 같다. 이 그림을 보면 제4군집이 중심적인 위치를 차지하고 있으며, 제3군집과 제2군집이 제4군집에 가깝게 있고 제1군집은 제일 바깥에 있는 것을 알 수 있다.
앞에서 본 바와 같이, 다차원척도분석, 군집 분석 및 네트워크분석에서 모두 11개 군집을 다시 4개 군집으로 분류할 수 있었다. 즉 독서분야는 독서교육을 핵심영역으로 독서교육의 이론, 독서정책, 독서운동의 4개 하위주제로 구분된다고 할 수 있다. 이런 분류과정을 표로 구현하면 <표 10>과 같다.
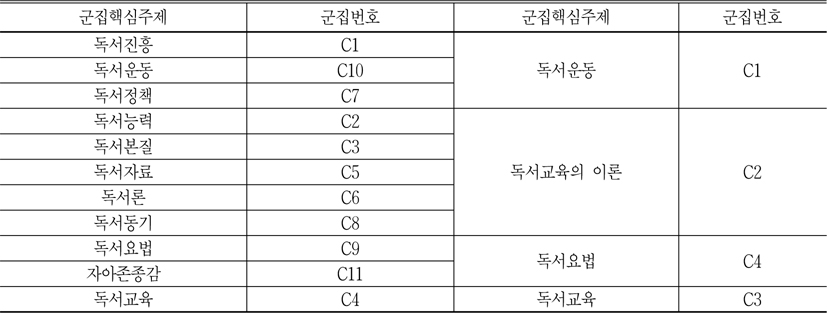
독서분야의 지식분류
독서분야의 지적구조의 군집별 변화를 확인하기 위하여 시기별 분석을 하였으며, 10년간의 문헌을 2003년에서 2007년 사이에 1기로, 2008년에서 2012년의 2기로 나누었다. 2기는 1기에 비하여 문헌의 성장을 비교하기 위하여 다음과 같은 공식을 이용하였다
WCGI=|2기문헌수-1기문헌수|*(2기문헌수 -1기문헌수)/(2기문헌수+1기문헌수)
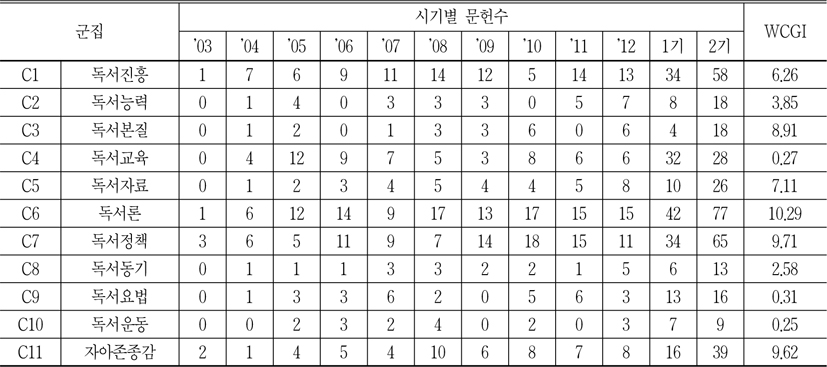
이 값이 클수록 2기문헌수가 1기문헌수보다 많이 증가하는 것을 뜻하고, 정적인 값을 갖는 것은 2기문헌수가 1기문헌수보다 성장하는 것이고, 음적인 값을 갖는 것은 2기문헌수가 1기 문헌수보다 감소하는 것을 의미한다(이재윤, 문주영, 김희정 2007).<표 11>은 각 군집별 문헌 수의 시기별 분석이다.
이 표에서 보는 바와 같이, 1기에 비하여 2기에 뚜렷하게 성장한 것은 군집 6(독서론) 및 군집 7(독서정책)이다. 뿐만 아니라 군집 내의 문헌수도 군집 6과 군집 7이 주도적으로 많은 것으로 나타났다. 문헌집합을 살펴보면 군집 6은 주로 2기에 한국어와 문화 분야에 주자, 정약용, 황덕길 등의 독서법이나 독서론에 대한 연구가많이 증가하였다. 군집 7과 같은 경우 1기에 비하여 독서정책이 더 깊게 연구되었다는 것을 알 수 있다. 예전의 종이책이라는 국한된 형식에서 벗어나 전자책 등 디지털화가 추진되고 있으며, 독서프로그램을 통하여 독서를 접하기 어려운 소외계층이나 장애인에게 유리한 독서정책을 수립하고, 한국뿐만 아니라 중국, 일본, 프랑스등 외국의 독서정책을 소개하는 등 다양한 독서정책과 관련된 논문들이 발표되었다.
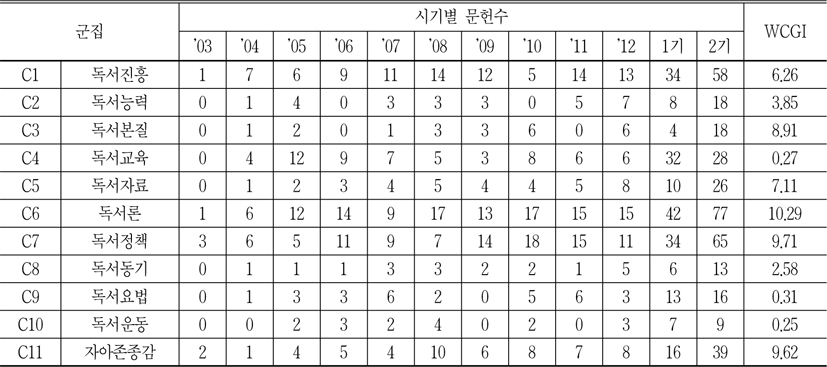
군집별 시기별의 문헌수의 변화
한편 문헌수는 많지 않지만 군집 11(자아존중감)의 문헌수의 성장이 두드러진 것으로 나타났다. 군집 11은 1기에 주로 자아존중감의 개념을 소개하는 것이 대부분이었지만, 2기에는 독자발달 차원에서 자아존중감 이론이 다양한 대상, 예를 들면, 초등학생, 소외계층아동, 이혼가정아동, 치매노인, 중년남성, 학습부진아, 읽기부진아, 조기퇴직자 등에 대한 실증적인 논문으로 많이 나왔다. 한편 1기에 비하여 2기에 군집내의 문헌수가 감소한 군집은 군집 4(독서교육)이다. 이것은 2기에 접어들면서 독서교육보다 독서본질, 독서능력 등 독서교육과 관련된 이론들에 오히려 치중한 결과로 해석할 수 있다.
시기별 군집내의 문헌수의 변화를 NodeXL에 시각화하면 <그림 10>, <그림 11>과 같다.
<그림 10>, <그림 11>을 비교해보면 앞의 <표 10>에서 보는 것을 시각화로 확인할 수 있다. 대체로 위의 11개 군집을 보면 주로 독서론, 독서정책, 자아존중감, 독서본질 등에 관한 군집의 문헌수가 많이 증가한 것으로 나타났다. 4개의 큰 군집을 보면 주로 독서교육의 이론, 독서요법, 독서운동에 관한 연구가 많이 수행된 것을 알 수 있다. 이것은 독서분야의 연구동향이 독서교육에 대한 이론적인 연구보다 독서본질에 대한 탐구, 독서운동 및 독서프로그램 범위의 확장, 대상 및 형식의 다양성 등 실증적이 고 심도있는 연구가 더 많아진 것에서 그 이유를 찾을 수 있다. 또한 독서교육은 1기에 비하여 오히려 연구가 감소한 것으로 나타났지만 여전히 독서분야에 삼각매개중심성, 즉 결속력이 강한 주제이며 독서분야의 핵심적인 연구영역이다.
이 논문에서는 혼합가중치를 적용한 단어동시출현분석 기법을 이용하여 독서분야의 지적구조를 파악하였다. 단어동시출현 분석을 위한 데이터로 KCI에서 2003년에서 2012년 10년 사이에 나타난 838편의 논문의 키워드를 대상으로 하였다. 혼합가중치를 적용한 단어동시출현 분석기법을 통하여 파악된 독서분야의 지적구조에서 얻은 결론은 다음과 같다.
첫째, 혼합가중치는 문헌을 등재한 학술지의 등급에 의하여 생성된 수평가중치와 문헌 내의 키워드의 위치에 의하여 생성된 수직가중치를 결합하여 산출한 것이다. 혼합가중치에 의한 행렬은 일반가중치에 의한 것보다 군집분석, 다차원척도분석, 네트워크 시각화에서 더 좋은 결과가 나타났다.
둘째, 혼합가중치에 의하여 생성된 키워드행렬이 더 좋은 결과가 나왔으며, 이 행렬을 중심으로 네트워크분석을 통하여 독서분야의 지적구조를 분석하였다. 독서분야의 56개 키워드를 분석하였는데, 독서교육을 중심으로 4개의 큰 주제 및 11개의 하위주제로 구분할 수 있었다.
마지막으로 독서분야의 지적구조의 군집별 변화를 확인하기 위하여 시기별 분석을 하였는데 독서론, 독서정책, 자아존종감은 1기에 비하여 뚜렷하게 성장한 반면에, 독서교육은 오히려 2기의 문헌수가 더 감소한 것으로 나타났다. 이는 독서분야의 연구동향이 독서교육에 대한 이론적인 연구보다, 독서본질에 대한 탐구, 독서운동 및 독서프로그램 범위의 확장, 대상 및 형식의 다양성 등 실증적이고 심도있는 연구가 더 많아진 것에서 기인한 것으로 보인다.